이번에는 " PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation " 논문의 Supplementary 리뷰로 돌아왔습니다!

Supplementary는 총 B ~ H 까지 총 7개의 파트로 구성되어 있습니다.
여기서 저는 다음과 같은 목차로 리뷰해보려고 합니다.
[목차]
C : neural network architectures 와 training hyper parameters 에 대해 디테일하게 알아보는 섹션
D : Detection pipeline 에 관해 디테일하게 알아보는 섹션
E : PointNet의 여러 응용 방법에 대해 알아보는 섹션
F : 더욱 디테일하게 PointNet 구조를 분석해보는 섹션
Section C : Network Architecture and Training Details

PointNet Classification Network
PointNet의 입력포인트 클라우드를 정규화하여 모델의 변환 불변성(invariance) 를 강화하는 역할을 합니다. PointNet에는 두 개의 Transformation Network 가 존재하며, 각각 다음과 같은 목적과 구조를 가집니다.
1. Transformation Network: 기본 구성과 역할
[첫 번째 transformation network]
- 입력으로 raw point cloud 를 받아 3 x 3 행렬을 예측(regress) 합니다.
- 이 네트워크는 각 포인트에 MLP (64, 128, 1024) 구조를 공유하여 적용하고, 각 층의 출력 크기나느 각각 64, 128, 1024 입니다.
- Max pooling 을 사용해서 포인트 간에 정보를 통합하고, 이어 fully connected layer 2 개를 통과하여 최종 3 x 3 행렬을 출력합니다.
- 각 fully connected layer 의 출력 크기는 512, 256 이며, 출력 행렬은 항등행렬(identity matrix)로 초기화됩니다.
- 모든 층에는 마지막을 제외하고 ReLU 활성화 함수와 배치 정규화(batch normalization)이 적용됩니다.
[두 번째 transformation network]
- 첫 번째 네트워크와 동일한 구조를 가지지만, 64 x 64 행렬을 출력하도록 설계 되었습니다.
- 이 행렬 또한 항등행렬로 초기화되며, 행렬을 직교(orthogonal)에 가깝게 만드는 정규화 손실(regularization loss) 이 softmax 분류 손실에 추가됩니다. 정규화 손실 가중치는 0.001로 설정되었습니다.
2. 학습 설정 (parameter)
- drop out : 마지막 fully connected layer 에 드롭아웃이 적용되며, keep ratio는 0.7 로 설정. 이는 네트워크가 과적합 되는것을 방지하기 위함입니다.
- decay rate (배치 정규화의 감쇠율) : init = 0.5, max=0.99
- Adam optimizer : init = 0.001, momentum = 0.9, batch_size = 32로 20 에포크마다 학습률을 절반으로 줄입니다.
- 학습 시간 : ModelNet 데이터셋에서 학습할 때, TensorFlow와 GTX1080 GPU 환경에서 3-6시간 정도 소요됩니다.
PointNet segmentation Network
1. PointNet 파트 세분화 네트워크의 기본 구조

- 입력 포인트 변환(T1) 및 특징 변환(T2) : T1과 T2는 입력 포인트와 특징의 정렬/변환을 담당합니다. 각 포인트와 특징에 대해 3 x 3 및 64 x 64 행렬로 변환을 적용하여 모델이 입력의 다양한 변환에 불변성을 갖도록 합니다.
- 완전 연결층(Fully Connected, FC) : 각 포인트에 완전 연결 층이 적용되며, 층의 출력 크기는 순서대로 n x 64, n x 128, n x 128, n x 512, n x 2048 입니다. 마지막 FC 층에서는 max pooling 을 통해 전역 특징(global feature)을 추출합니다.
- One-hot 벡터 추가 : 포인트 클라우드의 분류 레이블을 나타내는 크기 16의 one-hot 벡터가 네트워크에 추가됩니다. 이 벡터는 전역 특징에 결합되어 입력의 종류(예: 의자, 테이블 등)를 반영합니다.
2. 지역 및 전역 특징 결합
PointNet의 파트 segmentation 는 지역(local) 포인트 특징과 전역(global) 특징을 결합하여 각 포인트의 예측 성능을 높입니다.
- Max pooling 결과와 지역 특징의 결합: 두 번째 변환 네트워크(T2) 이후의 지역 특징과 max pooling 을 통해 추출된 전역 특징을 각 포인트에 대해 결합하여, segmentation 작업에 적합한 풍부한 특징 표현을 제공합니다.
- 스킵 연결(skip links): 서로 다른 층에서 추출한 지역 특징을 결합하는 스킵 연결을 추가하여, 세분화 네트워크로 들어가는 포인트 특징 입력이 더욱 풍부해지도록 했습니다.
3. MLP 및 출력
segmentation network 에서는 MLP (256, 256, 128)을 사용하여 각 포인트에 대해 segmentation 점수를 예측합니다. 최종 출력은 n x 50 크기의 파트 점수로, 각 포인트가 특정 파트에 속할 확률을 나타냅니다.
4. 학습 설정
- 드롭아웃 없음
- 학습 파라미터 : classification network 와 동일한 학습 파라미터를 사용하며, Adam 옵티마이저와 학습률 감소 기법이 적용된다.
Baseline 3D CNN Segmentation Network
ShapeNet 의 part segmentation 실험에서는 PointNet 의 세분화 네트워크와 기존의 전통적 세분화방법 두 가지, 그리고 3D 볼류메트릭 CNN 네트워크를 비교했습니다. 여기서는 3D CNN 을 활용한 기본 세분화 네트워크(baseline 3D CNN segmentation network)를 설명합니다.
1. 3D 볼류메트릭 CNN 네트워크 구조
3D CNN 네트워크는 VoxNet 이나 3DShapeNets 와 같은 잘 알려진 3D CNN 아키텍처를 확장하여, fully convolutional 방식으로 세분화를 수행하도록 설계되었습니다.
2. 입력 데이터 전처리 : Volumetric Representation
- Point Cloud 변환 : 입력 포인트 클라우드를 32 x 32 x 32 해상도의 점유 그리드(occupancy grid)로 변환하여 3D 공간을 voxel 로 나눕니다.
- 각 voxel 은 해당 위치에 점이 포함되는지 여부를 나타내며, 네트워크는 이 볼류메트릭 데이터를 바탕으로 segmentation을 수행합니다.
3. 네트워크 구성
- 3D Convolution Layer : 초기 특징 추출을 위해 stride 가 1인 32 채널 3D 컨볼루션 연산을 다섯 번 반복합니다. 이때 각 voxel 의 receptive field (수용 영역)는 19 입니다.
- 1 x 1 x 1 3D Convolution Layer : 이후에는 1 x 1 x 1 커널 크기를 가진 3D 컨볼루션 레이어들을 추가하여 최종적인 세분화 레이블을 예측합니다. 이 레이어들은 각 voxel 에 대한 세분화 점수를 계산합니다.
- 활성화 함수와 정규화 : 모든 레이어에 ReLU 활성화 함수와 배치 정규화(batch normalization)를 적용하며, 마지막 레이어에는 적용하지 않는다.
4. 학습 및 비교
- 범주(categories) 기반 학습 : 네트워크는 여러 객체 범주에 걸쳐 학습되지만, 다른 방법들과 공정하게 비교하기 위해 특정 객체 범주만을 고려하여 평가합니다.
즉, 이 3D CNN 기반의 볼류메트릭 segmentation network는 voxel을 활용해 3D 공간을 표현하고, 3D 컨볼루션을 통해 각 voxel 의 세분화 레이블을 예측합니다. PointNet과 달리, 입력을 volumetric representation으로 변환하는 전처리 단계가 필요하지만, 3D 데이터에서 보다 직관적인 3차원 특징을 추출할 수 있다는 장점이 있습니다.
Section D : 3D 객체 탐지 파이프라인 세부사항
Detection Pipeline 은 객체 탐지 시스템의 단계적인 절차를 의미하며, 특정 장면(Scene) 에서 객체의 위치와 범주를 찾기 위해 설계된 일련의 작업 흐름입니다. 각 단계는 입력 데이터를 변환하고 객체의 위치나 종류를 추론하기 위해 다양한 기법을 적용하며, 보통 다음과 같은 단계를 포함합니다.
1. 객체 제안 생성
• Connected Component 방법으로 같은 레이블의 인접한 점들을 묶어 객체 제안(클러스터)을 만듭니다.
• 클러스터가 200개 이상의 점을 포함할 경우, 이를 객체 제안으로 간주하고 경계 상자를 객체로 설정합니다.
• 각 객체의 점수는 해당 범주의 점수 평균으로 계산되며, 작은 제안들은 제거합니다.
2. 밀집 객체 해결
• 의자 등 밀집된 객체의 경우 Connected Component만으로는 구분이 어려워 슬라이딩 윈도우 방식을 사용해 탐지합니다.
• 이진 분류 네트워크를 통해 각 객체 범주를 학습하고, 비최대 억제(NMS)로 중복된 상자를 제거합니다.
• 최종 평가를 위해 Connected Component와 슬라이딩 윈도우의 결과를 결합합니다.
3. 평가
• 각 모델을 다섯 개의 구역에서 훈련하고, 나머지 한 구역에서 테스트합니다.
• 모든 테스트 결과를 모아 정밀도-재현율(PR) 곡선을 생성하여 평가합니다.
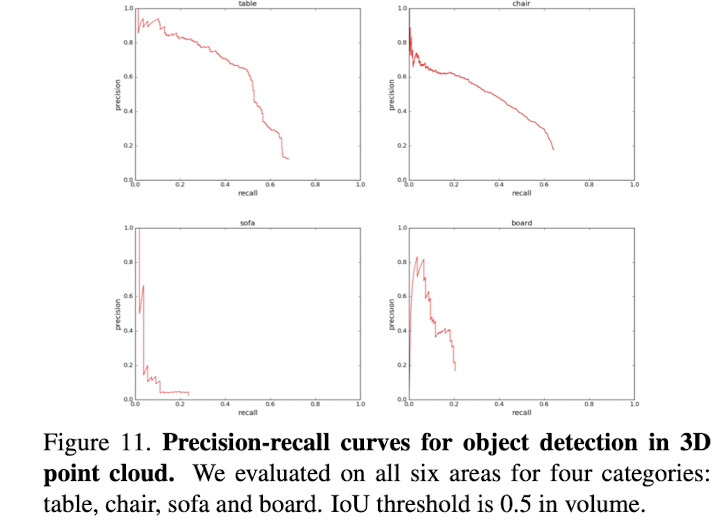
4. 후처리
• 불필요하게 작은 영역이나 부피의 객체는 제거합니다.
• 의자, 테이블, 소파 등의 바운딩 박스는 다리가 분리된 경우 바닥까지 확장합니다.
Section E : More Applications of PointNet
1. Bounding Box Adjustment
• Small Area Pruning: 작은 영역이나 부피는 탐지에서 제외하여 효율성을 높입니다.
• Bounding Box 확장: 테이블, 의자, 소파와 같이 다리가 분리된 객체는 바운딩 박스를 바닥까지 확장하여 더 정확하게 포착합니다.
2. Shape Retrieval (형상 검색)
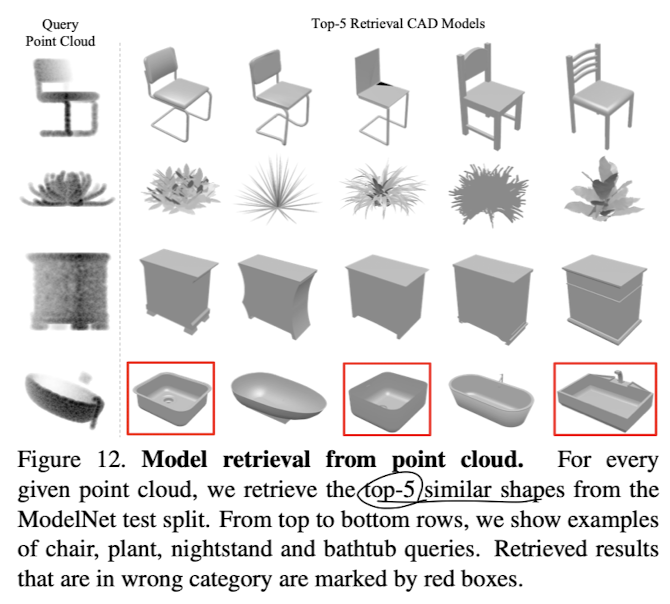
• PointNet은 입력된 포인트 클라우드의 글로벌 형상 시그니처를 학습합니다. 이는 서로 유사한 형태를 가진 객체들이 비슷한 시그니처를 가질 것으로 기대됩니다.
• 이를 테스트하기 위해, ModelNet 테스트 데이터셋에서 쿼리 형태의 글로벌 시그니처를 계산하고, 훈련 데이터셋에서 최근접 이웃 검색을 통해 유사한 형태를 검색합니다. 이 과정을 통해 형상 검색 애플리케이션을 구현할 수 있습니다.
3. Shape Correspondence (형상 대응)

• PointNet이 학습한 포인트 특징은 형상 대응을 계산하는 데 유용하게 쓰일 수 있습니다.
• 두 개의 유사한 객체(예: 두 개의 의자나 테이블)에서 중요한 포인트 집합을 추출한 후, 글로벌 특징에서 동일한 차원을 활성화하는 점들을 매칭하여 두 객체 간의 형상 대응 관계를 파악합니다.
Section F : More Architecture Analysis
1. 병목 차원 및 입력 포인트 수의 효과
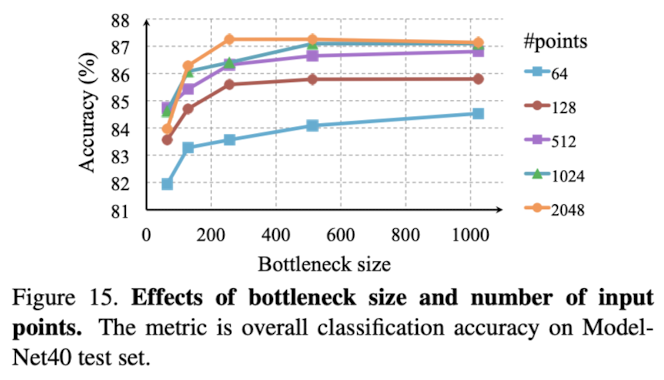
• 모델 성능은 입력 포인트 수가 증가할수록 향상되지만, 약 1,000포인트에서 성능이 포화됩니다.
• 최대 계층 크기(병목 차원)도 중요한 요소로, 이를 64에서 1024로 증가시키면 2-4%의 성능 향상이 나타나며, 다양한 3D 형상을 구별하기 위해 충분한 포인트 기능이 필요하다는 것을 시사합니다.
• 64개의 포인트만 입력해도 PointNet은 괜찮은 성능을 보입니다.
2. MNIST 숫자 분류

• 3D 포인트 클라우드 학습을 목적으로 하지만, 2D 포인트 클라우드(MNIST 픽셀 집합)에도 적용할 수 있으며, 성능이 괜찮습니다.
• CNN보다 성능은 낮지만, PointNet이 2D 이미지를 포인트 세트로 간주하여 처리할 수 있음을 보여줍니다.
3. 법선 벡터 예측

• PointNet의 세분화 버전에서는 로컬 및 글로벌 특징을 결합하여 로컬 포인트의 맥락을 제공합니다.
• 법선 벡터 예측을 통해 로컬 기하학적 특징을 학습할 수 있음을 입증했으며, PointNet의 예측이 보다 부드럽고 연속적으로 나타납니다.
• 위 그림 16은 PointNet의 법선 벡터 복원 결과를 보여줍니다. 왼쪽 열은 포인트넷의 예측 결과, 오른쪽 열은 실제 메쉬로부터 계산된 법선 벡터(ground-truth)입니다.
4. 세분화 강건성
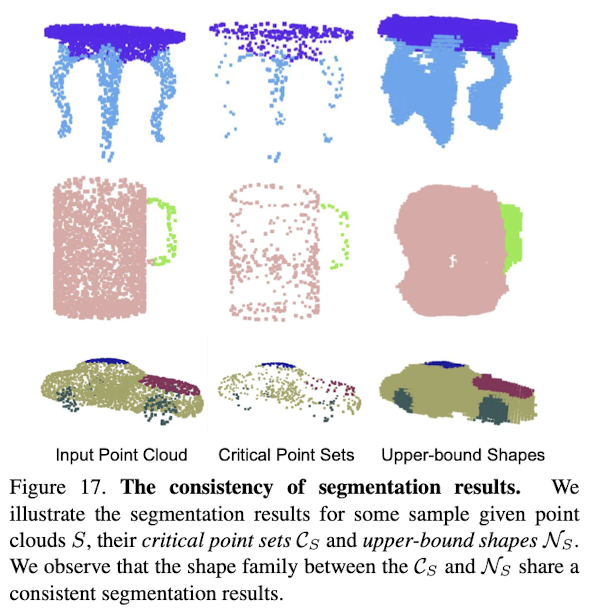
• PointNet은 데이터 손상 및 포인트 누락에 대해 강건합니다. 이는 전체 포인트 클라우드에서 중요한 포인트만을 통해 전역 형상 특징을 추출하기 때문입니다.
• 세분화 작업에서도 이러한 강건성이 유지되며, 입력 포인트 클라우드에 대해 일관된 세분화 결과를 제공합니다.
• 위 그림 17은 PointNet의 세분화(segmentation) 일관성을 보여줍니다.
• 왼쪽: 입력된 포인트 클라우드(3D 점들의 집합) S .
• 중간: 중요한 포인트들로 구성된 Critical Point Sets C_S . PointNet이 특정 형상을 인식하기 위해 핵심 포인트들만을 사용하여 학습한 결과입니다.
• 오른쪽: Upper-bound Shapes N_S 로, 각 객체의 세분화 결과입니다. 전체 형상을 고려하여 다양한 부분을 색상으로 구분합니다.
5. 새로운 형상 범주에 대한 일반화 능력

• PointNet은 훈련되지 않은 새로운 형상(예: 얼굴, 집, 토끼, 주전자)에도 일부 일반화됩니다.
• 포인트넷이 주로 평면 구조를 가진 인공 객체에 대해 학습되었음에도 불구하고, 새로운 형상들에 대해 일반화할 수 있음을 보여줍니다.
• 위 그림 18은 보이지 않은 객체에 대한 포인트넷의 일반화 능력을 보여줍니다.
각 행의 구성:
1. Original Shape (원래 모양): 각 객체의 실제 형상입니다.
2. Critical Point Sets (중요한 포인트 집합): PointNet이 형상을 인식하기 위해 중요한 포인트들로만 구성된 집합입니다.
3. Upper-bound Shapes (상위 경계 형상): 학습된 모델이 생성한 최종 세분화 결과로, 객체의 전체적인 형상을 나타내고 있으며, 다양한 색상은 깊이(depth) 정보를 표현합니다.



