Abstract
이 논문은 3D 이해가 부족한 생성 신경망의 문제를 해결하기 위한 새로운 접근법을 제시한다.
구체적으로 DeepVoxels 는 3D 장면의 복잡한 기하학을 모델링하지 않으면서도, 시점에 따라 달라지는 외형을 정확히 캡처할 수 있는 효율적인 3D 특징 임베딩을 제안한다. 이를 통해 새로운 시점에서 장면을 재구성하는 문제를 해결하고, 기존 방법들보다 더 높은 품질의 Synthesis 결과를 얻을 수 있다.
Introduction
Generative Machine Learning:
- 최근 몇 년 동안 Generative Machine Learning 기술이 크게 발전하여, 이미지 생성과 같은 작업에서 뛰어난 성과를 보여주고 있다.
- 변분 오토인코더(Aariational Autoencoders) 나 생성적 적대 신경망(Generative Adversarial Networks, GANs) 기반 보델들이 이미지 합성, 고해상도 이미지 생성, 그리고 조건부 생성 작업에서 높은 성능을 보였다.
View Consistency Challenge:
- 위와 같은 기술은 고품질 이미지 생성은 가능하지만, 동일한 장면에 대한 일관된 뷰를 생성하는 데 어려움이 있다.
- 여러 시점에서 장면을 생성하려면 네트워크가 3D 레이아웃을 이해해야 한다. 예를 들어, 의자가 다른 시점에서 어떻게 보일지 예측할 수 있어야 한다는 뜻이다...
- 그러나 기존의 2D Convolution Network 로는 3D 장면의 변환과 공간 배치를 학습하는 데 한계가 있다. => 3D 환경을 다루기 위한 복잡한 학습 과정이 필요하기 때문
Limitations of 2D Generative Models:
- 기존 U-Net 구조의 생성 네트워크는 저수준 특징을 효율적으로 전달하는 skip connection 을 사용하지만, 2D to 2D Mapping 은 큰 3D 변환에 대해 잘 일반화되지 않는 문제가 있다.
- 또한, 3D 장면의 기하학적 재구성에는 성공한 이후에도, 고해상도 색 정보를 처리하는데 한계가 있다. 이로 인해 사진처럼 사실적인 이미지 합성을 하는 데에 어려움이 있다.
3D Deep Learning Advances:
- 최근 3D Deep Learning 분야에서는 표면 기하학(Surface Geometry) 예측에서 높은 정확도를 보이고 있지만, 여전히 실제 이미지 합성에서는 한계가 있다.
- 3D 기하학을 표현하기 위한 다양한 방법(예: Point cloud, Mesh, Signed distance fields, occupancy grids) 이 있지만, 색상 정보를 고해상도로 처리하는 것은 여전히 해결되지 않은 문제이다.
Proposed Approach (DeepVoxels):
- DeepVoxels 는 기존 2D 생성 모델의 한계를 극복하기 위해 3D 연산을 Network Architecture 에 통합하는 방법이다.
- 3D 시점에서 직접적인 추론을 수행하고, 기하학적 모델링 없이 장면의 지속적인 잠재 표현(persistent latent representation) 을 학습하여, 새로운 시점에서의 장면 합성을 가능하게 한다.
- 이 방식은 2D 렌더링 네트워크와 결합하여, 3D 월드 공간에서의 지속적인 특징 볼륨을 활용해, 시점과 다중 뷰 기하학을 명확히 반영하며 훈련된다.
결국 이 논문에서 제안하는 주요 기술적 기여는 다음과 같다.
1. 지속적인 3D 특징 표현은 3D 장면의 기하학적 구조를 고려하여 이미지 합성에 필요한 정보들을 처리한다.
2. 부드러운 가시성(soft visiblity) 을 학습하여, 장면 내에서 가려지는 부분을 자연스럽게 추론하고 이를 통해 더 고해상도이고 일관된 이미지를 생성할 수 있다.
3. 미분 가능한 이미지(Differentiable image) 형성을 통해, 훈련 시 시점과 다중 뷰 기하학이 정확하게 반영되도록 유도하여 보다 신뢰성 있는 합성을 제공한다.
4. 3D supervision 없이 학습이 가능하다는 점은 DeepVoxels 가 기존 3D 모델처럼 복잡한 3D 데이터나 라벨이 필요하지 않음을 의미하며, 2D 이미지를 이용해 훈련할 수 있음을 나타낸다.
5. 이 논문에서는 3D 신경망 장면 표현이 기존의 기하학적 재구성 방법의 한계를 극복하고, 더 적은 데이터로도 일반화된 3D 재구성을 가능하게 한다는 점에 초점을 두고 있으며 빛의 반사로 생기는 광택 하이라이트나 다른 시점의 의존적 효과(예: 반사, 굴절 등)을 고려하지는 않는다.
Related Work
기존 연구들과 이 논문에서의 접근법을 비교한다.
1. 신경망 이미지 합성 : 기존에는 2D-to-2D 방식으로 이미지를 변환하는 방법들이 유망했지만, 3D 변환(회전, 원근 투영 등)에 대한 일반화에 어려움이 있었다. DeepVoxels 는 이를 극복하며 성능을 향상시킨다.
2. 3D 심층 학습 : 기존의 기하학적 재구성 방법들은 주로 기하학적 정보를 다루지만, DeepVoxels 는 3D 임베딩을 학습하여 새로운 뷰 합성을 목표로 한다.
3. 뷰 합성 : 2D 뷰를 잠재 공간에 임베딩하여 새로운 뷰를 생성하는 접근법들이 있지만, DeepVoxels 는 기하학적 제약을 고려하여 더 정밀한 결과를 만든다.
4. 모델 및 이미지 기반 렌더링
- 기존 연구 : 이미지 기반 렌더링(IBR)은 3D 장면을 정확하게 재구성하지 않고도, 기존의 이미지를 왜곡시켜 새로운 뷰를 생성하는 방법이다. 여기서 다중 뷰 기하학을 이용하여 새로운 이미지를 합성할 수 있지만, 이는 고해상도 사진을 생성하는 데 어려움이 있다. 일부 연구는 광선 필드를 이용하거나, 3D 점 구름과 같은 기법을 통해 렌더링을 시도했으나, 항상 비현실적인 아티팩트나 이미지 품질 저하가 발생할 수 있다.
- DeepVoxels는 기하학적 모델을 명시적으로 사용하지 않고도 3D 장면의 외관을 학습하여, 기존 방식보다 더 정밀하고 자연스러운 뷰 합성을 가능하게 만든다. 이 논문에서는 잠재 공간 임베딩을 통해 새로운 뷰를 디코딩하며, 기하학적 왜곡 없이 고해상도의 이미지를 생성할 수 있다.
Method
1. DeepVoxels 특징:
- 시점 불변성(viewpoint-invariant), 지속성(persistant), 균일성(uniform) 을 가진 3D 복셀 그리드로 구성
- 시점에 영향을 받지 않고 공간적 구조 유지
2. 구성 요소 역할:
- 3D 네트워크: 공간 구조와 논리를 처리
- 2D 네트워크: 섬세한 이미지 세부 사항을 생성
3. 학습 방식:
- 다중 시점 이미지를 사용
- 대상 시점의 기준 뷰 볼륨(canonical view volume) 을 입력으로 받음
- 3D 구조에 대한 명시적 감독(ground truth) 는 요구하지 않음.
Training Corpus

1. 데이터셋 구조:
- 하나의 소스 뷰 S_i : 이미지와 카메라 위치/자세 포함
- 두 개의 타겟 뷰 T_i0, T_i1 : 학습을 위한 새로운 시점을 나타냄
2. 샘플링 방법:
- 다중 시점 이미지(multi-view images) 를 기반으로 소스와 타겟 뷰를 구성
- T_i0와 시점 각도가 비슷한 상위 5개의 소스 뷰 중 하나를 선택(randomly)하여 S_i 로 설정
3. 이점
- 의미 있는 그래디언트 흐름: 학습 중 매번 적절한 데이터를 사용하도록 보장
- 다중 시점 일관성: 여러 시점에서의 이미지 일관성(Multi-view consistency) 촉진
- 동적(Dynamically) 샘플링: 고정된 데이터셋이 아니라 학습 중 무작위로 데이터를 선택
Architecture Overview
위 아키텍처는 Encoder-Decoder 기반 구조로 볼 수 있으며, 지속적인 3D DeepVoxels 표현이 잠재 공간(latent space) 역할을 한다.
💡 잠재 공간(latent space) 란?
데이터의 내재된 특성(representation) 을 축약적으로 표현한 공간이다. 복잡한 데이터를 저차원이나 더 추상적인 형태로 변환해, 데이터를 효과적으로 분석하거나 처리할 수 있도록 돕는 개념이다.
잠재 공간의 역할
1. 데이터 압축
- 원래 데이터는 고차원(예: 이미지의 픽셀 값)으로 표현된다.
- 잠재 공간은 데이터를 핵심적인 정보로 압축하여 저차원으로 표현한다.
2. 의미 있는 특징 추출
- 잠재 공간에 있는 점(벡터)은 원래 데이터의 중요한 특성을 포함한다.
- 예를 들어, 얼굴 사진 데이터를 잠재 공간으로 변환하면, 이 공간은 얼굴의 주요 특징(눈, 코, 입의 위치 등)을 나타낼 수 있다.
3. 복원 가능성
- 잠재 공간에서 데이터를 다시 원래의 데이터 형태로 복원할 수 있다.
- 예 : Autoencoder 의 디코더가 잠재 공간에서 데이터를 복원
위의 아키텍처는 훈련 과정에서 소스 뷰 S_i 를 인코더에 입력하여 타겟 뷰 T_i 를 예측한다. 구체적 단계는 다음과 같다.
1. 2D 특징 추출
: 소스 뷰에서 2D feature map 을 추출하기 위해 2D feature extraction network 를 사용한다.
2. 3D 특징 표현 학습
: 시점에 독립적인 3D 특징 표현을 학습하기 위해, 추출한 2D 이미지 특징을 차별화 가능한 리프팅 레이어를 통해 명시적으로 3D 로 변환한다.
💡Lifting Layer 란?
Lifting Layer 는 2D 이미지를 3D 표현으로 변환하는 계층으로, 딥러닝에서 공간적 구조를 학습하거나 3D 데이터를 생성하기 위한 핵심 요소이다. DeepVoxels 에서는 이 계층을 통해 2D 특징을 3D 특징 볼륨으로 확장하며, 이후의 네트워크가 이를 활용해 새로운 시점의 이미지를 생성한다.
3. DeepVoxels 융합
: 리프팅된 3D 특징 볼륨은 우리의 지속적인 DeepVoxels 장면 표현과 융합되며, 이는 게이트 순환 네트워크(gated recurrent network) 를 통해 이루어진다. 지속적인 3D 특징 복륨은 GRU (Gated Recurrent Unit) 의 히든 상태(hidden state) 로 사용된다.
💡GRU (Gated Recurrent Unit) 란?
GRU는 순환 신경망(Recurrent Neural Network)의 변형된 형태로, 장기 의존성(long-term dependency) 문제를 해결하기 위해 설계된 구조이다. RNN 의 단점인 기울기 소실 문제(gradient vanishing)를 완화하며, 적은 파라미터 수로 LSTM 과 유사한 성능을 낸다.
- 게이트 기반 구조
GRU는 두개의 게이트를 사용하여 정보를 효율적으로 조정한다.
- 업데이트 게이트 : 중요한 정보를 선택적으로 기억하고 이전 정보를 유지.
- 리셋 게이트 : 과거 정보를 얼마나 "지울지" 결정
- 메모리 셀 없이 간단한 구조
GRU는 LSTM과 달리 별도의 메모리 셀(ceel state)을 사용하지 않고, 은닉 상태(hidden state)를 통해 정보를 전달한다.
- 연산 효율성
- LSTM 보다 파라미터 수가 적고, 학습과 추론 속도가 더 빠르다. => 연산 자원이 제한적인 환경에 적합
4. 3D 컨볼루션 처리
: 특징 융합 이후, 3D 컨볼루션 네트워크가 특징 볼륨을 처리한다.
5. 투영 및 좌표 변환
: 처리된 볼륨은 차별화 가능한 재투영 레이어를 통해 두 타겟 뷰의 카메라 좌표계로 매핑되어, 표준 시점 볼륨(canonical view volume)을 생성한다.
6. 폐색(Occlusion) 처리
: 구조화된 폐색 네트워크(structured occlusion network) 는 표준 시점 볼륨에서 보이지 않은(voxel visibility) 영역을 판단하며, 볼륨을 2D 뷰 특징 맵으로 평탄화한다. (Fig. 3 참조)
7. 2D 렌더링
: 학습된 2D 렌더링 네트워크가 이 맵을 사용해 최종적으로 투 개의 타겟 뷰 이미지를 출력한다.
이 네트워크는 종단 간(end-to-end)으로 학습되며(모델 복잡도를 최소화할 수 있음), 3D 도메인에서 명시적인 감독(supervision)이 필요없다.
2D 재랜더링 손실(re-rendering loss) 를 통해 예측 결과가 타겟 뷰와 일치하도록 학습된다.
Camera Model
이 논문에서는 원근 투영(perspective) 기반의 핀홀 카메라 모델을 따른다. 이 모델은 외부 파라미터(Extrinsics)와 내부 파라미터(Intrinsics)로 정의된다.
1. 외부 파라미터 (Extrinsics)
: 카메라가 세계 좌표계(World Coordinate System) 에서 어떻게 배치되는지 나타낸다.

위 식에서 R 은 전역 카메라 회전(Global camera rotation)을 나타내는 회전 행렬(3x3)이다.
위 식에서 t 는 카메라의 평행 이동(translation)을 나타내는 벡터(3x1)이다.
| 표기식은 수학적으로 "행렬을 옆으로 결합한다.(concaternate)" 는 뜻이다.
3x3 크기의 회전 행렬(Rotation Matrix)인 R과 3x1 크기의 변환 벡터(Translation Vector)인 t를 가로로 결합하여 3x4크기의 행렬이 된다.
=> 이렇게 R 과 t 를 하나의 행렬로 합쳐서 사용하는 이유는, 회전 및 이동(변환)을 한 번에 표현하기 위해서이다.
2. 내부 파라미터 (Intrinsics)
: 카메라 렌즈와 센서의 특성을 정의한다.

센서의 크기, 초점 거리, 왜곡 효과 등을 포함한 행렬이다. 3x3 행렬이다.
3. 월드 좌표 -> 카메라 좌표계로의 Mapping
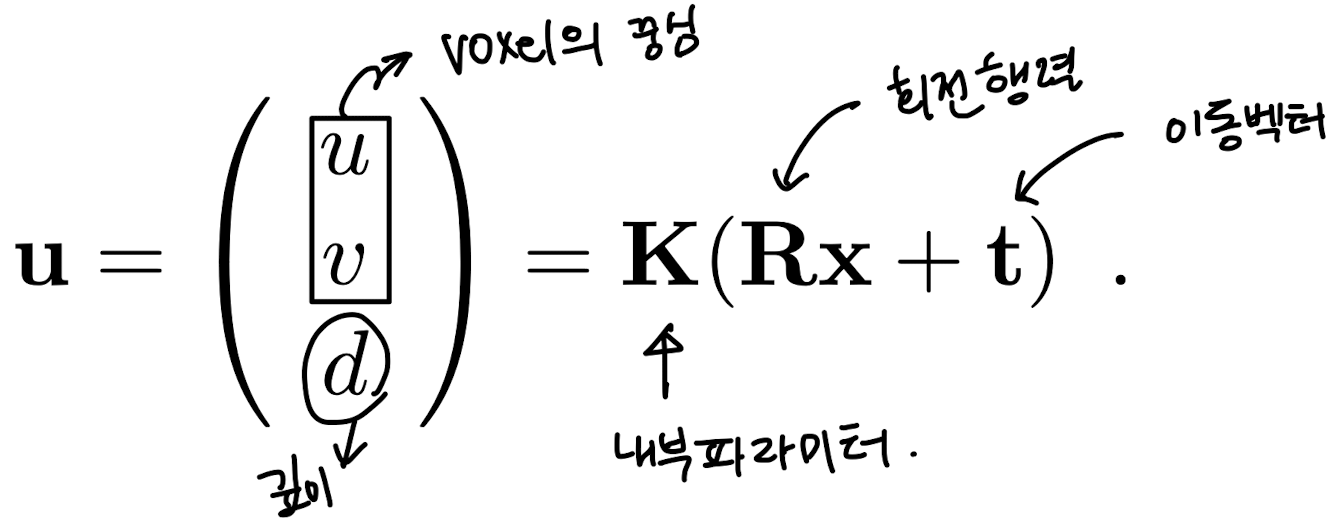
- x: 월드 좌표에서의 점
- R: 3x3 회전 행렬 (카메라의 회전 방향 표현)
- t: 3x1 이동 벡터
- K: 3x3 카메라의 내부 파라미터 행렬 (초점 거리, 왜곡 등 표현)
- u, v: 2D 화면상의 픽셀 좌표
- d: 해당 점의 깊이(depth), 즉 카메라에서의 거리
과정:
1. Rx + t: 월드 좌표 x 를 카메라 좌표계로 변환
2. K(Rx + t): 변환된 좌표를 카메라의 내부 파라미터로 변환하여 스크린 좌표로 매핑
4. 카메라 좌표계 -> 월드 좌표로의 역매핑
스크린 좌표u, v와 깊이 d가 주어졌을 때, 원래 3D 월드 좌표 x 를 찾는 공식
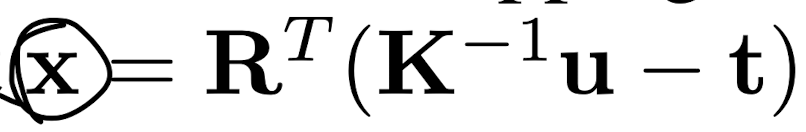
- 역매핑 설명:
1. K^-1u: 스크린 좌표를 3D 카메라 좌표로 역변환
2. -t: 카메라의 위치를 반대로 적용
3. R^T: 회전 행렬의 전치 행렬을 사용하여 회전 변환을 역으로 수행
Feature Extraction
입력 이미지로부터 2D 특징 맵(feature map)을 추출하기 위한 방법에 대해 설명한다.
1. 입력 이미지의 Down Sampling
- 이미지는 stride-2를 사용하는 Convolutional layers 를 연속적으로 통과하여 다운 샘플링된다.
- 최종적으로 해상도 64x64로 축소된다.
- Stride-2: 컨볼루션의 이동 간격을 2로 설정하여 공간적 해상도를 줄이는 효과를 낸다.
2. U-Net 아키텍처 사용
- 다운 샘플링된 이미지는 U-Net 구조를 사용하여 처리된다.
- U-Net
- 일반적으로 의료 영상 처리에서 사용되는 네트워크 구조로, 이미지를 다운 샘플링하면서 중요한 공간 정보를 보존한다.
- 이후 업샘플링(복원) 과정에서 이 정보를 활용하여 고품질의 출력을 생성한다.
- 여기서는 최종적으로 64x64 크기의 feature map 을 추출하는데 사용된다.
3. 결과물
- 최종적으로 추출된 64x64 크기의 2D 특징 맵은 이후 3D 공간으로 확장되는 Volume lifting 의 입력으로 사용된다.
Lifting 2D Features to 3D Observations
2D 이미지 특징을 3D 로 변환하여 장면을 더 입체적으로 이해하도록 만든다. 이렇게 변환된 3D 볼륨은 DeepVoxels 라는 지속적 3D 표현으로 통합된다.
3D 볼륨은 장면 중심(중력 중심) 근처에 배치되며, 이는 희소 번들 조정(Sparse Bundle Adjustment)을 통해 추정된 키포인트 데이터를 이용해 계산한다.
💡 여기서, 희소 번들 조정(Sparse Bundle Adjustment) 이란? => 카메라와 3D 포인트 간의 관계를 추정하는 기법으로, 희소한 키포인트 데이터를 이용해 장면의 대략적인 구조를 계산한다.
볼륨 크기는 장면 전체를 포함하도록 설정하되, 공간 해상도를 잃지 않도록 최대한 작게 제한한다.
리프팅 구현
- Gathering Operation
: 각 Voxel 중심의 위치를 소스 이미지의 2D 공간으로 투영한다. Equation 1. 참고
이때 투영된 위치를 기반으로 양선형 샘플링(Bilinear Sampling) 을 수행하여 해당 위치에서 특징 벡터를 추출한다.
추출된 특징 벡터는 보셀의 코드 벡터에 저장된다.
💡 Bilinear Sampling 이란? => 2D 이미지에서 특정 위치의 특징을 추출할 때, 주변 픽셀 값의 가중 평균을 계산하여 부드러운 특징 값을 얻는 방법이다.
또한 장면의 깊이 맵(Depth) 나 기하학적 정보(Scene Geometry) 가 주어지지 않는다.
=> 대신, 게이트 순환 네트워크(Gated Recurrent Unit) 를 통해 3D에서 깊이 불확실성을 자동으로 학습하고 해결한다.
Integrating Lifted Features into DeepVoxels
GRU 를 사용하여 2D 이미지 피처를 3D 볼륨에 변환(lifting) 하고, 이를 기하학적으로 일관된 DeepVoxels 표현으로 점진적으로 통합한다. 이는 단순히 3D 관측 데이터를 쌓는 대신, 훈련 데이터 전반에 걸쳐 일관된 볼륨 표현을 생성한다.
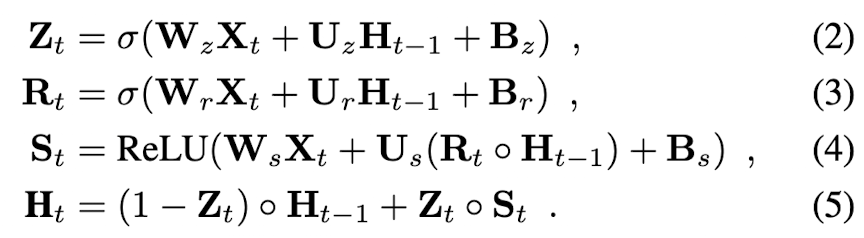
< GRU 의 작동 방식 >
- 업데이트 게이트(Eq.2) : 이전 Hidden state H_t-1 를 얼마나 유지할지 결정한다.
현재 timestep t의 lifted 3D 피처 볼륨 X_t, 이전 hidden state H_t-1, 그리고 trainable weights(W, U) 및 biases(B)를 입력으로 받아 계산한다. 이후 시그모이드 활성화 함수를 사용하여 값은 낸다.
- 리셋 게이트(Eq.3) : 이전 정보를 얼마나 초기화할지 결정한다. 이 또한 시그모이드 활성화 함수를 사용한다.
- 새로운 피처 제안(Eq.4) : 현재 lifted feature X_t 와 이전 hidden state 를 조합해 새로운 피처를 제안한다.
여기서 Rt dot H_t-1 는 voxel 단위의 리셋된 이전 hidden state 를 의미한다. 새로운 피처에서는 ReLU 활성화 함수를 사용한다.
- 새로운 hidden state(Eq.5) : 업데이트 게이트를 통해 새로운 정보와 이전 정보를 결합한다.
이전 상태 H_t-1 과 새로운 DeepVoxel 제안 S_t 의 선형 조합으로 현재 hidden state 를 계산한다.
<체적 및 구조>
- GRU 는 각 voxel 에서 작동하며, 모든 voxel 이 각 시점에서 독립적으로 업데이트 된다.
- 모든 voxel은 f 개의 feature channel 을 갖고 있어 높은 차원의 표현을 저장할 수 있다.
- 이후 GRU 를 3D inpainting U-Net 을 적용해 이 피처 표현에서 누락된 부분을 채운다. ("복원한다" 라고 볼 수 있다)
- 학습 중 사용된 복잡한 lifting layer 와 GRU 를 제거해 효율성을 높히고 학습된 DeepVoxels 는 새로운 뷰에서 이미지를 생성하는 데만 사용된다.
주요 이점은 다음과 같다.
- 지속적인 상태 유지: GRU 의 hidden state 를 초기화하지 않아 기하학적 일관성을 보장한다.
- 최적의 3D 표현 학습: lifted 관측 데이터와 hidden state 를 결합해 최적의 3D feature 를 학습한다.
- 테스트 시 불필요한 단계(2D feature extraction, lifting layer, GRU gate)는 제거하여 성능을 최적화 한다.
Projection Layer
Projection Layer 는 3D 벡터를 특정 카메라의 관점(타겟 뷰) 으로 변환하는 과정을 담당한다.
- Lifting Layer 에서는 2D 피처를 3D 로 변환했지만, 프로젝션 레이어는 이를 반대로 변환한다.
- 삼선형 보간법(trilinear interpolation) 을 사용해 월드 스페이스의 그리드에서 필요한 값들을 계산하여 타겟 뷰에서 사용할 수 있는 3D 볼륨으로 만든다.
(삼선형 보간법을 이용해 보간된 코드 벡터를 추출하고, 이를 기준 뷰 볼륨(canonical view volume) 의 피처 채널에 저장한다.)
- 최종적으로, 타겟 뷰의 기준 좌표계에서 재구성된 데이터를 제공한다.
이 단계는 모델이 다각도에서의 3D 구조를 이해하고 2D 이미지를 생성할 수 있도록 지원하는 중요한 역할을 한다.
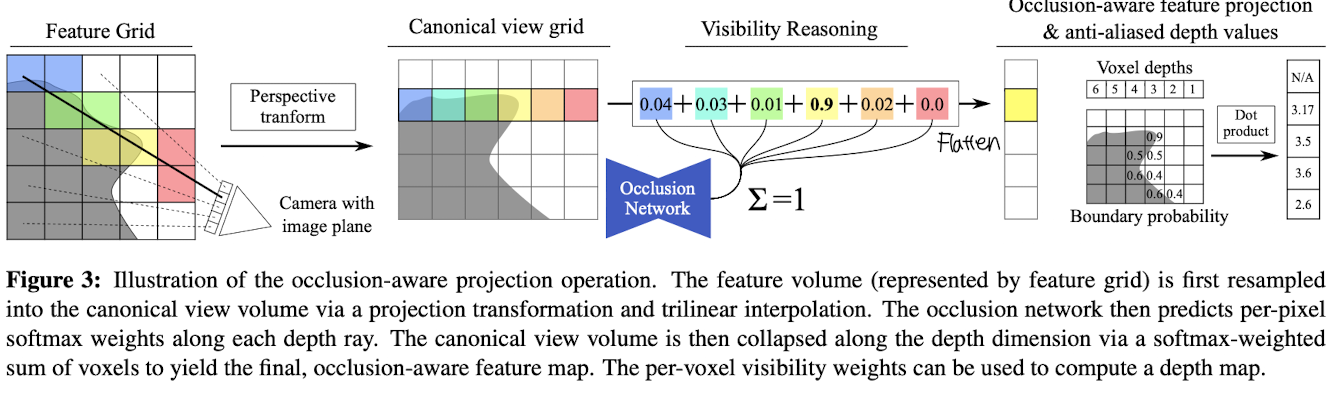
Fig 3. Occlusion-Aware Projection Operation 설명
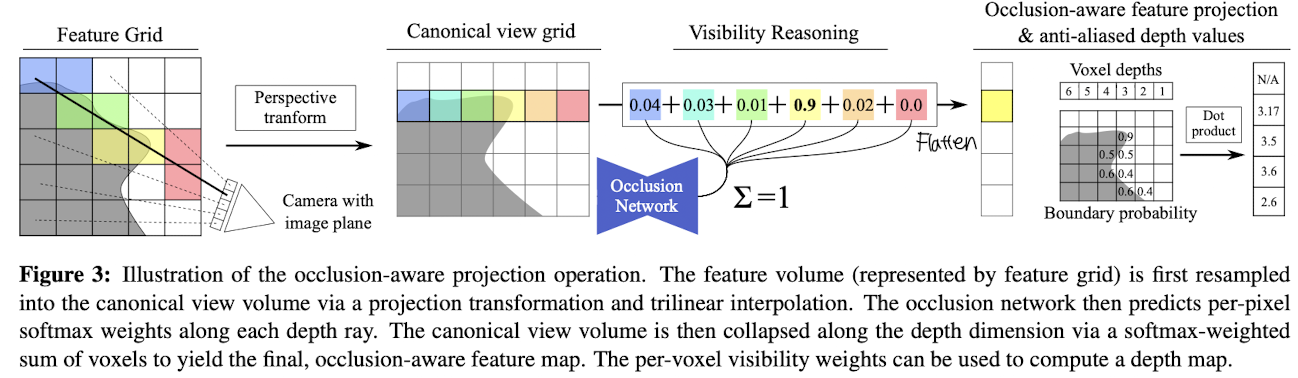
Occlusion-Aware Projection Operation 은 모델이 장면에서 폐색(occlusion, 한 물체가 다른 물체를 가려 보이지 않는 현상) 을 고려하여 더 정확한 3D 표현을 생성하도록 돕는 과정이다.
- 피처 볼륨(feature volume, 피처 그리드로 표현됨)은 먼저 프로젝션 변환(projection transformation) 과 삼선형 보간(trilinear interpolation) 을 통해 기분 뷰 볼륨(canonical view volume)으로 리샘플링 된다.
- Occlusion network (폐색 네트워크) 는 각 깊이 광선(depth ray) 를 따라 각 픽셀 당 소프트맥스 가중치(softmax weights)를 예측한다. 이 가중치는 해당 깊이의 voxel 이 얼마나 "보이는지"를 나타낸다.
- 이후, 기준 뷰 볼륨(canonical view volume) 은 깊이 차원을 따라 소프트맥스 가중치를 사용한 가중합(softmax-weighted sum)으로 축소된다. 이를 통해 최종적으로 폐색을 고려한 피처 맵(occlusion-aware feature map, 2D 이미지) 이 생성된다.
- 각 voxel 의 가시성 가중치(per-voxel visivility weights) 는 깊이 맵 (depth map) 을 계산하는 데 사용할 수 있다.
Occlusion Module
폐색(occlusion) 추론은 정확한 이미지 생성 및 새로운 관점으로 일반화하는 데 필수적이다. 이를 위해서, 각 voxel 의 소프트 가시성(soft visibility) 을 계산하는 전용 폐색 네트워크(occlusion network) 를 제안한다.
- 기준 뷰 볼륨(canonical view volume) 에서 타겟 뷰의 각 픽셀은 하나의 voxel 열(column) 로 표현된다. (Fig 3. left 참고)
- 먼저, 이 voxel 열은 카메라와의 거리를 나타내는 피처 열(feature column) 과 결합된다. 이는 폐색 네트워크가 voxel 순서를 추론할 수 있게 한다.
- 이후, 이 기준 뷰 볼륨 내 각 voxel 의 피처 벡터는 단일 3D 컨볼루션 계층을 통해 차원이 4 인 저차원 피처 벡터로 압축된다.
- 이 압축된 볼륨은 폐색 추론을 위한 3D U-Net 의 입력으로 사용된다.
- 이 네트워크는 각 레이(ray, 단일 픽셀 열로 표현됨) 에 대해 softmax 활성화를 기반으로 voxel 별 가시성 가중치(스칼라)를 예측한다. (Fig 3. middle 참조)
- 그런 다음, 기준 뷰 볼륨은 예측된 가시성 값을 사용한 가중 평균(weighted average) 를 통해 깊이 차원에서 flattening (평탄화) 된다.
- 소프트맥스 가중치는 depth map 을 계산하는 데도 사용할 수 있으며, 이는 네트워크의 폐색 추론 과정을 이해하는 데 도움을 준다. (Fig 3. right 참조)
Rendering and Loss
1. 렌더링 네트워크 : 모델이 새로운 뷰(novel view)에서 이미지를 생성할 수 있도록 설계된 구조이다.
- 입력: 폐색 네트워크로부터 나온 3D 기준 뷰 볼륨(이미 평탄화된 형태)
- U-Net 아키텍처:
- 입력 데이터를 처리하고, 이미지의 전역 정보를 이해하도록 학습한다.
- 이후 전치 컨볼루션(transposed convolution) 을 사용하여 픽셀 수준의 출력(이미지)를 생성한다.
- 전치 컨볼류션은 낮은 해상도를 높은 해상도로 업샘플링하는 과정에 사용된다.
2. 손실함수 : 모델 학습에 사용된 손실함수는 두가지가 결합된 형태이다.
- l1 손실: 예측된 이미지와 실제 이미지 간의 차이를 절대값으로 측정한다.
이 손실은 모델이 전체적으로 정밀한 출력을 내는 데 도움을 준다.
- 적대적 손실(adversarial loss):
- 적대적 생성 네트워크(GAN) 의 개념을 활용한다.
- 판별기(discriminator) 는 예측 이미지가 진짜인지 가짜인지 판단하며, 생성기(generator) 는 판별기를 속이도록 이미지를 생성한다.
- 교차 엔트로피 손실(cross-entropy loss): 판별기가 진짜/가짜 여부를 학습하도록 돕는 주요 손실 함수이다.
3. 적대적 판별기 (discriminator)
- 패치 기반 : 이미지를 전체적으로 판단하는 대신, 패치(작은 부분) 단위로 판단한다.
이렇게 하면 모델이 국소적인 디테일(예: 텍스처) 을 더 잘 학습할 수 있다.
4. 최적화 방법
- ADAM 옵티마이저 :
- 딥러닝에서 일반적으로 사용되는 최적화 알고리즘이다.
- 학습 속도가 빠르고, 모델이 더 안정적으로 수렴하도록 돕는다.
Analysis
Dataset and Metrics
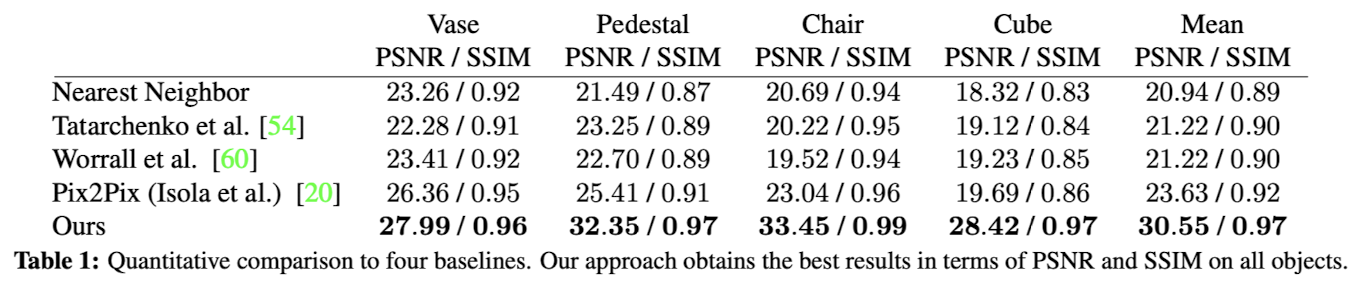
모델의 성능은 4개의 고품질 3D 스캔 데이터를 렌더링하여 얻은 합성 데이터(Synthetic data)에서 평가한다. (Fig 4. 참고)
1. 데이터 전처리
: 각 스캔 데이터를 원점(origin) 에 중심화하고, 크기를 단위 정육면체(unit cube) 내에 맞게 조정한다.
2. 훈련 데이터셋
: 물체를 북반구에서 균일하게 분포된 479개의 카메라 위치에서 렌더링하여 생성
3. 테스트 데이터셋
: 물체를 북반구의 아르키메데스 나선(Archimedean spiral)에서 1000개의 새로운 카메라 위치에서 렌더링하여 생성
4. 이미지 해상도
: 모든 이미지는 1024x1024 해상도로 렌더링되며, 이후 면적 평균(area averaging) 을 사용하여 512x512 해상도로 축소해 aliasing(앨리어싱, 계단 현상, 날카로운 선의 왜곡 형상)을 최소화한다.
5. 평가 지표
- PSNR (Peak Signal-to-Noise Ratio): 복원된 이미지와 원본 이미지 간의 차이를 평가하는 지표로, 값이 클수록 품질이 높음을 의미한다.
- SSIM (Structural Similarity Index): 이미지의 구조적 유사성을 평가하는 지표로, 시각적으로 더 유사한 이미지를 측정한다.
Implementation
- 프레임워크 : PyTorch 를 사용해 모델 구현
- Voxel 볼륨: 기본적으로 32^3 voxels 크기의 큐브 볼륨 사용
- 손실 함수:
- L1 손실은 이미지 픽셀 전체에 대해 평균 계산
- L1 손실과 적대적 손실의 가중치 비율은 200:1
- 훈련
- 옵티마이저: ADAM
- 학습률: 4 x 10^-4
- 장면별로 학습을 진행하며 수렴할 때까지 훈련
- 모델 크기: 아키텍처는 1억 7천만 개의 파라미터를 포함
- 테스트 성능: 한 프레임 렌더링 시간 71ms
Baselines
DeepVoxels 모델 성능을 비교하기 위해 세 가지 강력한 Baseline 모델을 사용
1. Pix2Pix 기반 모델:
- 입력: 픽셀별 뷰 방향(카메라 원점에서 각 픽셀까지의 정규화된 벡터)
- 기능: 입력 이미지에서 타겟 컬러 이미지를 생성
- 특징 : 2D 이미지 간 변환 성능을 대표
2. Deep Autoencoder 기반 모델:
- 입력:
- 타겟 뷰와 가장 가까운 Top-5 이웃 중 하나
- 타겟 뷰와 입력 뷰의 포즈 정보(깊은 잠재 공간(latent space)에서 결합)
- 기능: 타겟 뷰와 입력 뷰 간의 관계를 학습
3. Rotation-Equivariant Latent Space 기반 모델:
- 입력: 타겟 뷰와 가장 가까운 Top-5 이웃 중 하나
- 기능:
- 입력 뷰를 타겟 뷰로 변환하는 회전 행렬을 통해 잠재 공간을 회전
- 해석 가능한 회전 등가 잠재 공간 학습
Baseline 의 학습 및 평가 조건
- 학습조건: 모든 모델은 동일한 손실 함수를 사용해 수렴할 때까지 학습, 입력 데이터는 DeepVoxels 와 동일
- 테스트조건: Top-1 이웃을 입력으로 사용하여 가장 관련 있는 정보를 제공
- 파라미터 수 : DeepVoxels와 비교 가능한 수준으로 맞춤, 일부는 약간 더 많은 파라미터 포함
Object-specific Novel View Synthesis
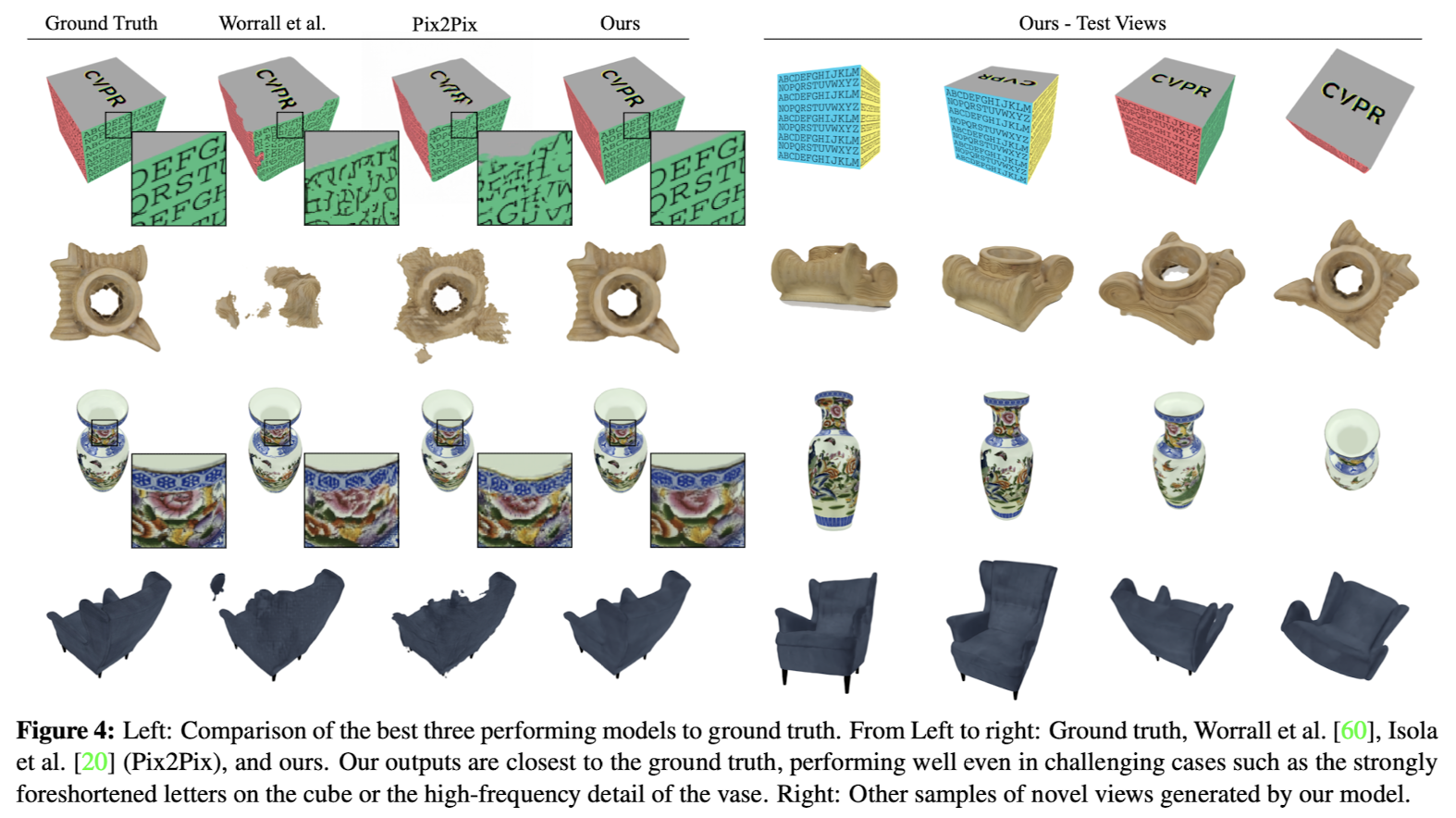
실험
- 네트워크와 Baseline 모델을 고품질 3D 스캔의 합성 렌더링 데이터로 학습
- 평가 지표: PSNR, SSIM
결과 비교
- Pix2Pix: 가장 성능이 좋은 Baseline 모델 => 기하학적 제약을 사용하지 않았음에도 우수한 성능(예상 외의 결과...)
- 제안된 모델: 모든 Baseline 을 평균 7dB 이상 성능으로 압도
제안된 모델의 특징 및 장점들 🔻
• 제안된 모델의 특징:
1. 질 높은 3D 추론:
• 훈련 중 보지 못한 뷰에서도 성능 저하 없이 부드럽게 추론.
• Baseline은 훈련 데이터에서 본 뷰로 “고정(snap)“되는 경향이 있음.
2. 일관된 다중 뷰 제약:
• 제안된 잠재 공간이 명시적으로 다중 뷰 제약(투영 및 에피폴라 기하학)을 적용해 일반화 성능 향상.
• Baseline 모델은 이를 명시적으로 적용하지 않아 잠재 공간 표현이 제한적일 수 있음.
3. 세밀한 디테일 표현:
• 이미지 해상도의 1/16 크기의 저해상도 voxel grid를 사용하면서도 작은 디테일(큐브의 글자, 화병의 세부 사항)까지 포착.
• Trilinear Interpolation이 리프팅 및 투영 단계에서 세밀한 표현 학습에 기여.
• 결론 및 시각적 비교:
• 제안된 모델은 퀄리티와 일반화 측면에서 Baseline보다 뛰어나며, 도전적인 경우에서도 강력한 3D 추론을 보여줌.
• 비디오: 테스트 경로를 따라 부드럽게 동작하는 모습을 시각적으로 확인 가능.
• 보충 자료: 추가 합성 장면 제공.
Voxel Embedding vs. Rotation-Equivariant Embedding(Worrall et al. 모델)
1. 성능 차이
: 본 논문에서 제안하는 모델은 다중 뷰 기하학(multi-view geometry)에 의해 제약을 받는 반면, [60]의 모델은 더 많은 자유도를 가진다. 즉, 제안된 모델은 여러 뷰에서 일관된 3D 구조를 유지하려는 제약이 있지만, [60]는 이러한 제약이 부족하여 오버피팅 위험이 크다.
2. 깊이 맵
: 제안된 모델은 occlusion reasoning 을 통해 깊이 맵을 명시적으로 계산하지만, [60] 모델은 이를 고려하지 않는다.
3. 제안된 모델은 매개변수를 훨씬 적게 사용하여 메모리 효율성이 높다.
Occlusion Reasoning and Interpretability
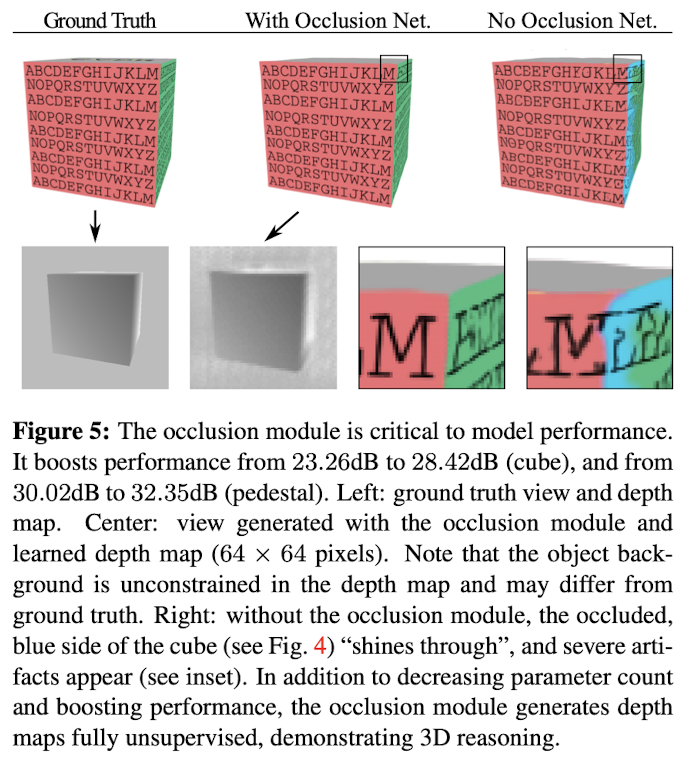
1. 문제 사항
: 렌더링 파이프라인에서 depth test는 필수적인 부분이다. 렌더링 네트워크는 출력 뷰를 예측할 때 occlusion 문제를 고려해야한다.
만약 깊이 차원을 평탄화(Flatten) 하고 2D convolution을 사용하여 특징을 줄이려는 단순한 접근법을 사용하면, 네트워크의 매개변수 수가 급격히 증가하고, 학습 중에는 여러 깊이에서 온 특징들이 동일하게 결합외어 출력 색상을 예측할 수 있다. 그러나 추론 중에는 객체의 가려진 부분이 나타나는 (shining through) 심각한 아티팩트가 발생할 수 있다. (Fig 5. right)
2. 해결책
: 제안된 occlusion 네트워크는 각 RAY 마다 복셀들을 softmax 가중 합으로 결합하도록 강제해서 여러 깊이에서 복셀을 결합하는 것을 벌칙으로 부과한다. 이 방법을 통해 기존의 네트워크보다 더 좋은 성능을 낼 수 있다. (Fig 5. middle)
3. 깊이 맵
: Occlusion 모델이 생성한 깊이 맵은 이 모델이 실제로 3D 구조를 학습하고 있음을 입증한다. 이 깊이 맵은 비지도 학습 방식으로 학습되며, 가장 관련 있는 복셀을 선택해야 하는 필요성에 의해 자연스럽게 발생한다.
Novel View Synthesis for Real Captures

- 학습 데이터: 이 네트워크는 DSLR 카메라로 촬영한 실체 캡처 이미지를 사용하여 학습되었음
- 카메라 파라미터: 카메라의 포즈, 내부 카메라 파라미터, 키포인트 point cloud 는 희소 번들 조정(sparse bundle adjustment)를 통해 얻어진다.
- 복셀 그리드 설정: 복셀 그리드의 원점은 해당 point cloud 의 무게 중심(center of gravity)에 맞춰 설정된다. 복셀 그리드의 해상도는 64로 설정되며, 각 복셀을 8개의 특징 채널을 저장한다.
- 테스트 트랙: 테스트 중에는 무작위로 선택된 두 개의 학습 포즈를 선형 보간하여 테스트 트랙을 만든다.
- 결과 : 음료수와 지구본은 눈에 띄는 반사광(specular)을 가지고 있지만 네트워크는 이를 잘 처리했다.
Limitations
1. 메모리 비효율성
: 사용된 3D 볼륨은 구조적으로 메모리 효율이 낮다. 따라서 공간 범위를 확보하기 위해 local 해상도를 희생해야한다.
현재 모델은 64^3 복셀 해상도와 8개의 특징 채널로 훈련할 수 있으며, 12GB 메모리를 사용하는 GPU를 가득채운다.
2. 소규모 해상도에서의 성과
: 상대적으로 작은 볼륨 해상도에서도 이미 설득력 있는 결과를 얻을 수 있었다.
Conclusion
본 연구에서는 DeepVoxels 라는 새로운 3D 구조화 장면 표현 방법을 제안했다. 이 방법은 2D 감독(supervision) 만을 사용하여 3D 장면의 관점 의존적 외관(view-dependent appearance)을 인코딩한다.
- 이 접근법은 3D 구조 신경 장면 표현(3D-structured neural scene representations) 의 첫걸음이다.
- 또한 기존의 2D 생성 모델의 근본적인 한계를 극복하기 위해 네트워크에 3D 연산(native 3D operations) 을 도입했다.



